
How an Ops Compliance team turned thousands of dense legal PDFs into clean, auditable data — using n8n, a data warehouse, object storage, and a large multimodal LLM — and why almost none of the hard engineering happened in the AI itself.
Note on this writeup: This is a design-level breakdown of a real production system. Specific identifiers — table names, bucket names, queries, webhook URLs, and credentials — have been intentionally generalized so the architecture can be discussed openly without exposing anything sensitive.
The Problem: An Audit That Doesn’t Scale With Headcount
Every home-equity loan a lender originates comes wrapped in a legal agreement — typically ten, twenty, sometimes fifty pages of dense language covering APRs, fee schedules, draw periods, repayment periods, billing-error procedures, and maturity terms. Agreements like these usually sit under federal lending-disclosure frameworks such as Regulation Z, which is exactly why fields like APR, fee disclosures, and billing-error rights carry outsized weight in an audit. Get one of those values wrong — or worse, fabricate one — and you don’t just have a data quality issue. You have a compliance finding.
For a full compliance audit, someone has to read all of it, across thousands of agreements, and pull out roughly a hundred discrete data points from each one — consistently, and without inventing anything that isn’t actually on the page.
That’s not a task humans do well at scale. Reading is slow, attention degrades after the two-hundredth document, and “I’m pretty sure it said that” is not an acceptable standard of evidence in a regulatory audit. So instead of hiring more reviewers, the Ops Compliance team built a machine to do the reading — one that runs every ten minutes, never re-reads a document it’s already processed, and never trusts its own AI component further than it can verify.
This article walks through exactly how that system is built, why each design decision exists, where the approach is genuinely clever, and where it still has rough edges worth knowing about before you build something similar.
At a Glance
- What it does: Extracts ~100 structured fields from each home-equity loan agreement PDF and writes them into a warehouse table, ready for audit.
- What it’s built on: n8n for orchestration, object storage for source PDFs, a data warehouse for state and output, and a multimodal LLM for the actual reading.
- What makes it interesting: The pipeline has no job queue, no manual progress tracking, and almost no trust placed in the AI step — yet it’s fully idempotent, versioned, and self-healing after a crash.
- The real artifact: Not the workflow wiring — the prompt. It encodes actual business policy, including a three-step decision tree for one of the gnarlier fields in the schema: loan maturity.
Evaluating something similar for your own document backlog? Talk to LnP Infotech’s engineering team — this is the kind of system we build.

System Architecture: Three Workflows Wearing a Trench Coat
Strip away the n8n canvas and the system is really three cooperating workflows, each with a single job:
| Component | Trigger | Responsibility |
|---|---|---|
| Orchestrator | Runs every 10 minutes | Decides what’s left to process, batches it, and fans work out to the workers |
| Concurrency Guard | Called by the orchestrator | Answers “is a run already in progress?” — prevents overlapping executions |
| Batch Workers (×10) | Triggered via webhook by the orchestrator | Each does the actual reading: download → LLM → parse → store |
The orchestrator wakes up on a fixed schedule, and the first thing it does is check its own pulse. Before touching a single document, it calls the guard workflow and asks, in effect, “Am I already running somewhere?” If a live execution is already in flight, the orchestrator throws a hard error and exits immediately — no queuing the request, no silent retry, just a clean stop. That single check eliminates an entire category of bugs: double-processing, race conditions on the output table, and two executions fighting over the same batch of documents. Manual runs are deliberately carved out as an exception — if a human explicitly kicks off a run, the guard lets it through regardless, because a person triggering it on purpose is a different risk profile than a cron job overlapping with itself.
This is a small piece of plumbing, but it’s the kind of thing that’s easy to skip early and expensive to add later. Concurrency bugs in scheduled pipelines tend to surface only under load — exactly when you can least afford to debug them.
Solving the “What’s Left to Do” Problem — Without a Job Queue
Most batch-processing systems need some kind of job table: a list of pending work, a status column, maybe a claimed_by field to prevent two workers from grabbing the same row. This system skips all of that, and the way it skips it is the most quietly elegant part of the design.
Instead of maintaining a separate queue, the orchestrator’s very first action is to query its own output table — the destination where finished results land — and ask it for every loan ID that’s already been processed under the current schema version. That list becomes the “already done” set.
The next query is where the actual business logic lives, and it does a lot of work in a single statement. It finds home-equity loans that:
- have a stored agreement document available,
- have reached “offered” status,
- aren’t internal test accounts,
- fall within the relevant action-year window, and
- are not already in the “already done” list from the previous step.
It sorts the remaining candidates by recency and caps the result at a few hundred rows.
The effect is that the destination table is the queue. There’s no separate tracking mechanism to keep in sync, no risk of the job table and the results table drifting apart, and — critically — the system becomes naturally idempotent. If the pipeline crashes halfway through a run, the next scheduled trigger simply re-queries the output table, sees what’s missing, and picks up exactly where it left off. There’s no cleanup step, no “did the last run finish?” logic, no manual intervention. Restarting is free.
Why this matters more than it looks: A huge amount of pipeline fragility comes from state living in two places that can disagree — a queue that says a job is “in progress” while the results table says it never landed. By making the results table the single source of truth for “what’s done,” this design makes that entire failure mode structurally impossible.
The schema-version tag layered into this query is what makes the design future-proof rather than just clever. When the extraction prompt changes — say, the maturity-date logic gets refined — the team bumps the schema version, and every previously-processed loan suddenly looks “unprocessed” again under the new version. The whole backlog gets reprocessed under the improved logic without anyone touching old rows or writing a one-off migration script.
Fan-Out, Fan-In: Parallelizing Without Losing Control
A few hundred PDFs is too much for one worker to chew through sequentially within a reasonable window, so the orchestrator splits the batch round-robin across ten identical workers and fires ten parallel HTTP webhooks, each carrying its own slice of the work.
Orchestrator
├── Query: what's already done? (read output table)
├── Query: what's eligible and not done? (business rules + exclusion list)
├── Split batch round-robin → 10 slices
├── Fire 10 webhooks in parallel ──► Worker 1 ─┐
│ ► Worker 2 ─┤
│ ► ... ├──► Merge node (barrier)
│ ► Worker 10 ─┘
└── Run complete once all 10 report back
A merge node sits at the end of the orchestrator as a synchronization barrier — it waits for all ten workers to report back before considering the run finished. This is a standard fan-out/fan-in pattern, but it’s worth calling out because it’s doing real work: it turns ten independent, asynchronous processes into one coherent “run” with a clean start and end, which makes monitoring and alerting far simpler than if the ten workers were left to report success or failure independently with no shared completion signal.
Inside a Worker: The Read–Verify–Store Loop
Each of the ten workers runs the same loop, one document at a time:
- Download the agreement PDF from object storage.
- Send it to the LLM with a long, carefully engineered extraction prompt.
- Parse the model’s JSON response.
- Insert the structured row into the warehouse.
If parsing or insertion fails, the worker pings a Slack channel and moves on to the next document rather than halting — a single bad document doesn’t take down the batch. Between documents, the worker pauses briefly (a second or three), a small courtesy that keeps the pipeline from hammering the LLM API past its rate limits during a burst of ten parallel workers.
It’s a deliberately unglamorous loop. Nothing about it is clever in isolation — and that’s the point. The complexity in this system isn’t distributed evenly across the pipeline; it’s concentrated almost entirely in one place.
The Prompt Is the Product
If you stripped this system down to its single most valuable artifact, it wouldn’t be the n8n canvas, the warehouse schema, or the webhook wiring — it would be the prompt sent to the LLM. Everything else is plumbing built to support what that prompt produces.
Rule One: Don’t Think, Read
The prompt opens by telling the model exactly what role it’s playing: a precise financial-document data extractor, not an analyst and not a guesser. Then it states the single rule that everything else hangs on:
Do not infer or guess. If a field’s information is not explicitly stated in the document, return an empty string.
For most use cases, a model that fills small gaps with reasonable inference is a feature. For an audit, it’s a liability. A hallucinated APR isn’t a rounding error — it’s a fabricated finding that could misrepresent a borrower’s actual loan terms in a regulatory record. The prompt trades away the model’s “helpfulness” instinct on purpose, because in this context, an honest blank is worth more than a confident guess.
Rule Two: JSON Is a Contract, Not a Suggestion
A surprising amount of the prompt is spent defending the structural integrity of the output itself: escape internal quotes, avoid stray backslashes, never leave a literal newline inside a string value, mentally check that every bracket closes before answering. That level of obsessiveness isn’t paranoia for its own sake — it’s hard-won experience. Downstream, a code node runs a literal JSON.parse() on the model’s response. One malformed character and that entire document’s extraction is lost, no partial credit. So the prompt treats valid JSON as a non-negotiable contract rather than a best-effort hope.
Rule Three: Normalize at the Source
Rather than handing the warehouse messy, inconsistent formatting and cleaning it up downstream, the prompt pushes normalization upstream into the extraction step itself: percentages come back as 5.99%, currency as $500, and every date — regardless of how it’s written in the source document — gets coerced into a single canonical MM/DD/YYYY format. By the time a row lands in the warehouse, it’s already clean and directly queryable, with no separate transformation layer required.
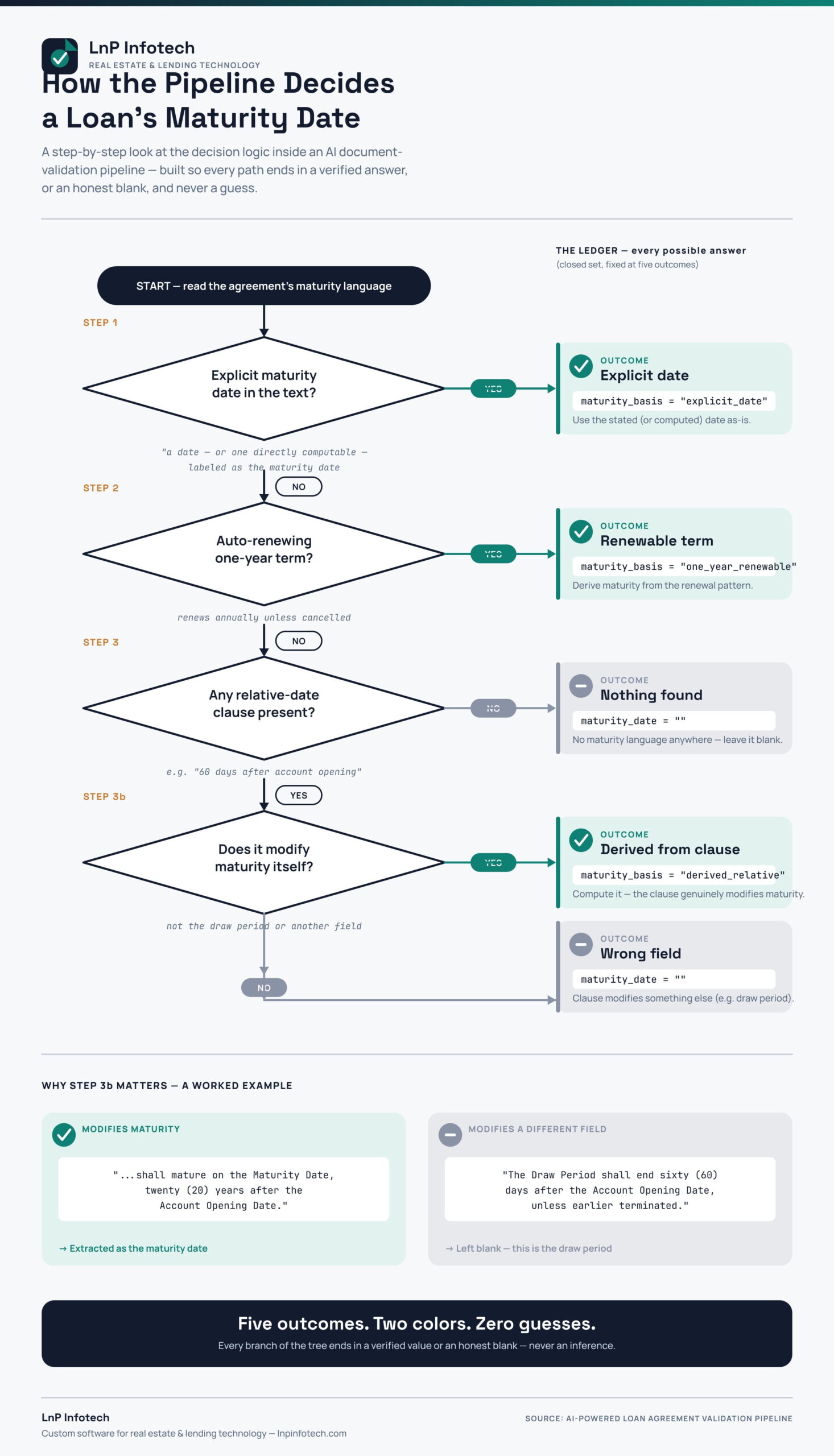
Rule Four: Encode the Actual Business Policy — Maturity Logic
This is the part of the prompt that earns its complexity. A loan’s maturity date can be expressed in a handful of structurally different ways in the source text, and they are not interchangeable. The prompt encodes a genuine three-step decision tree to handle this:
Step 1 — Look for an explicit maturity date. If the document states a calendar date (or a directly computable one, like “twenty years after the Account Opening Date”) and labels it as the maturity or loan-end date, use it. Mark the field’s basis as an explicit date.
Step 2 — Fall back to a renewable-term pattern. If there’s no explicit maturity date, check whether the agreement instead describes a one-year renewable term — language indicating the loan automatically renews annually unless cancelled. If so, derive maturity from that pattern instead and mark it accordingly.
Step 3 — Disambiguate relative date references. This is the delicate one. Agreements often contain clauses like “measured from sixty days after the Account Opening Date” — and that offset might describe the maturity date, or it might describe something else entirely, like the end of the draw period. The model has to determine, from surrounding context, which figure that offset actually modifies.
A worked, illustrative example makes the distinction concrete:
- Positive case: “This Agreement shall mature… on the Maturity Date, which is the date that is twenty (20) years after the Account Opening Date.” → This explicitly labels the computed date as maturity. Extract it as the maturity date.
- Negative case: “The Draw Period shall end sixty (60) days after the Account Opening Date, unless earlier terminated.” → The sixty-day offset here modifies the draw period, not maturity. A naive pattern-matcher might grab “60 days after account opening” and misfile it as a maturity date. The prompt has to recognize the surrounding label and correctly leave the maturity field blank if no separate maturity clause exists.
That distinction — knowing which noun a relative date clause is actually attached to — is genuinely hard to get right with simple keyword matching, which is exactly why it’s been pushed into the LLM with explicit worked examples rather than handled with brittle regex in code.
Rule Five: A Fixed, Closed Schema
The prompt closes by specifying the exact set of roughly one hundred keys the model is allowed to return, with explicit instructions to use only those keys. This isn’t a style preference — those keys map one-to-one onto the columns of the warehouse insert downstream. A model that decides to rename a field or add a helpful extra one would silently break the insert step, so the schema is treated as a closed contract, not a loose suggestion.
Trust, But Mostly Verify
What’s most notable about this system, taken as a whole, is how little faith it places in its own AI component. The model’s raw output is regex-extracted, parsed inside a try/catch block, checked explicitly for errors, and only then written to the warehouse — with Slack alerts wired independently into both the parsing step and the insertion step. The LLM isn’t treated as an oracle. It’s treated as exactly what it is: a powerful, occasionally unreliable component that needs to be wrapped in guardrails on every side, the same way you’d treat a third-party API with no SLA.
This is the architectural philosophy worth taking away even if you never build this exact pipeline: the model does the reading; the surrounding code decides whether to believe it.
Why This Design Holds Up
- It’s idempotent. Because “what’s done” lives in the output table itself, restarts are free and double-processing is structurally impossible — there’s no separate state to fall out of sync.
- It’s versioned. A schema-version tag lets the team revise the extraction prompt and reprocess the entire backlog under improved logic, without manually clobbering or migrating old results.
- It’s auditable. Alongside every derived value, the pipeline also stores the raw source sentence it was extracted from — so a human auditor, or a regulator, can trace any single number straight back to the exact line of text that produced it.
- It fails loudly. Hard errors go to Slack immediately and stop the run rather than letting corrupted or partial data quietly land in the warehouse.
Where It Could Bite
No design is free of trade-offs, and this one has a few worth watching:
- The static per-run cap assumes a steady backlog. Pulling a fixed “few hundred” documents every ten minutes works fine until intake volume spikes — at which point the backlog will quietly grow faster than the pipeline can clear it, with no built-in signal that it’s falling behind.
- Round-robin batching ignores document size. Splitting work evenly by count rather than by page count or file size means one unlucky batch of unusually large agreements could brush up against the ten-minute execution window while the other nine workers sit idle, finished early.
- Alerting only catches hard failures. A parse error or a failed insert trips Slack immediately — but a field that quietly comes back as an empty string when it absolutely should have had a value won’t trigger any alarm at all. Silent under-extraction is the harder failure mode to catch, and right now nothing is watching for it.
- Business logic is duplicated, not centralized. The maturity decision tree — and every other rule — lives inside each of the ten workers’ prompts independently. Change the policy, and you’re changing it in ten places unless those workers are pulling from one shared prompt source, which creates real risk of silent drift between workers over time.
Reasonable mitigations, if you’re building something similar: size-aware batching instead of pure round-robin, a backlog-depth metric that scales the per-run cap dynamically, a centralized prompt store that all workers reference rather than ten independent copies, and a lightweight statistical check that flags when a given field’s empty-rate spikes unexpectedly across a run — a strong signal that something in the source documents or the model’s behavior has shifted.
The Bigger Pattern: AI as a Component, Not a Brain
It’s tempting, when an LLM can read a hundred-page legal agreement and pull structured terms out of it, to treat the model as the whole system. This pipeline is a useful counter-example. The intelligence is real and genuinely hard to replicate any other way — but it’s boxed in on every side by deterministic plumbing: a SQL query that encodes the business eligibility rules, an idempotent loop that always knows what’s already done, and parse-and-alert guardrails that assume, correctly, that the model will sometimes get it wrong.
That pattern generalizes well beyond home-equity loans. Lease agreements, title commitments, purchase-and-sale contracts, property management agreements, mortgage servicing disclosures — anywhere a real estate or lending business has a pile of dense legal documents and a recurring need to pull the same handful of fields out of every one of them consistently, this same shape applies: deterministic orchestration around an LLM reading step, with verification at every handoff and audit traceability baked in from the start.
Lessons for Teams Building Something Similar
If you’re evaluating whether to build a comparable pipeline for your own document-heavy workflow, a few principles from this design are worth carrying over regardless of the specific tooling you choose:
- Let your output table double as your queue when possible — it removes an entire class of state-synchronization bugs.
- Version your extraction logic explicitly, so policy changes can trigger a clean, full reprocessing run instead of a manual one-off migration.
- Write the “don’t guess” instruction into the prompt explicitly, and mean it — for any compliance-adjacent use case, an honest blank beats a confident hallucination every time.
- Store the source evidence alongside every derived field. Auditability isn’t a nice-to-have bolted on later; it’s much cheaper to design in from the start.
- Never let the model’s output touch your system of record without a parse-and-verify step in between. Treat it like any other unreliable third-party dependency.
- Watch for silent failure modes, not just loud ones. A field that’s wrongly empty is a worse problem than a parse error, because nothing tells you it happened.
Build Something Like This With LnP Infotech
LnP Infotech builds custom software for real estate, lending, and property technology companies — including AI-powered document automation pipelines like the one described above. If your team is buried in manual review of loan agreements, leases, title documents, or property management contracts, our engineers can help you design a pipeline that’s idempotent, auditable, and built to survive contact with real-world documents.
Talk to our engineers about your project →
Frequently Asked Questions
What does it mean for a data pipeline to be idempotent?
An idempotent pipeline produces the same end state no matter how many times it runs, including after a crash or a restart. In this system, that’s achieved by having the orchestrator check its own output table for completed work before deciding what to process next, rather than relying on a separate, easily desynchronized job queue.
Can large language models be trusted for compliance-grade document extraction?
Not on their own. The model in this pipeline is explicitly instructed never to infer or guess, and every output it produces is parsed, validated, and checked before it’s allowed to touch the system of record. The reliability comes from the surrounding guardrails — the verification layer, not the model’s raw judgment.
Why use a workflow tool like n8n instead of a custom backend service?
n8n lets a team express orchestration logic — scheduling, fan-out, concurrency control, error alerting — visually and quickly, without standing up and maintaining a dedicated backend service for what is fundamentally a batch-processing job. For teams that need to iterate on business rules frequently (as this maturity-logic example shows), that speed of iteration matters.
How do you prevent an LLM from hallucinating values in legal document extraction?
Three things in combination: an explicit “do not guess, return empty if not stated” instruction in the prompt; a verification step downstream that parses and validates the model’s output before storage; and an audit trail that stores the raw source sentence behind every extracted value, so any output can be checked against the original text.
Is this approach limited to home-equity loans?
No — the underlying pattern (deterministic orchestration, an LLM reading step bounded by strict instructions, and a verify-before-store guardrail) applies to any dense legal or financial document type, including mortgage servicing files, lease agreements, title commitments, and property management contracts.